

سیستم کشف تقلب و یادگیری ماشینی:
در دنیای علم داده، متدولوژی و الگوریتمهای زیادی وجود دارند که به طور دقیق، حجم زیادی از دادههای کاربر را به کار میگیرند. کارشناسان یادگیری ماشین آنها را بسته به مجموعه داده های موجود به دو سناریو اصلی تقسیم می کنند:
سناریو ۱: مجموعهی داده، دارای تعداد کافی نمونه تقلب است.
در این مورد، یادگیری ماشین کلاسیک یا تکنیکهای مبتنی بر آمار برای شناسایی حملات متقلبانه به کار میرود. این شامل آموزش یک مدل یادگیری ماشین یا به کارگیری الگوریتمهای کافی برای تخمین قانونی بودن تراکنش است. ما در اینجا متداولترین الگوریتمهای مورد استفاده را مرور میکنیم.
سناریوی 2: مجموعه داده نمونه تقلبی ندارد یا فقط تعداد بسیار کمی از آنها وجود دارد.
در صورتی که هیچ یک از اطلاعات قبلی در مورد تراکنشهای جعلی ذخیره نشده باشد، مدل یادگیری بر اساس نمونههایی از معاملات قانونی ساخته شده است.

مدلهای یادگیری ماشینی در سیستمهای کشف تقلب:
قبل از مرور مدلهای یادگیری رایج دیگر که برای کشف تقلب استفاده میشوند، باید گفت که اکثریت آنها اهداف مشابهی دارند و تنها در ویژگیهای ریاضی با یکدیگر متفاوت هستند. از این رو، دادههای موجود در انتخاب مدلهای یادگیری مناسب به جای خود الگوریتم، عاملی تعیینکننده در نظر گرفته میشوند. برخی از این مدلها عبارتند از:
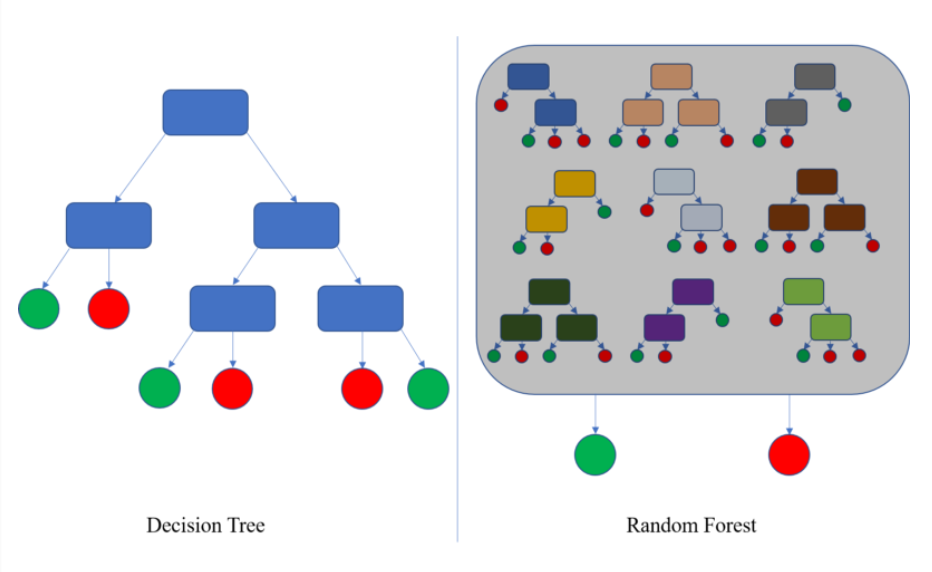
جنگل های تصادفی یا جنگلهای تصمیم گیری تصادفی: این الگوریتم شاخههای تصمیمگیری را ترکیب میکند و دادههای از دست رفته، نویز، نقاط پرت و خطاها را بهطور دقیق تجزیه و تحلیل میکند. این الگوریم در دستهبندی سریع است و در نتیجه در میان متخصصان تشخیص تقلب به یکی از ارجحیتها تبدیل شده است.
شبکه های عصبی مصنوعی (ANN): این سیستم عملکرد مغز را برای انجام وظایف با یادگیری از گذشته، استخراج قوانین و پیش بینی فعالیتهای آینده بر اساس شرایط فعلی شبیه سازی میکند. این سیستم میتواند می تواند با طبقه بندی یک ورودی در گروه های از پیش تعریف شده، تقلبی بودن یا نبودن تراکنش را پیش بینی کند.

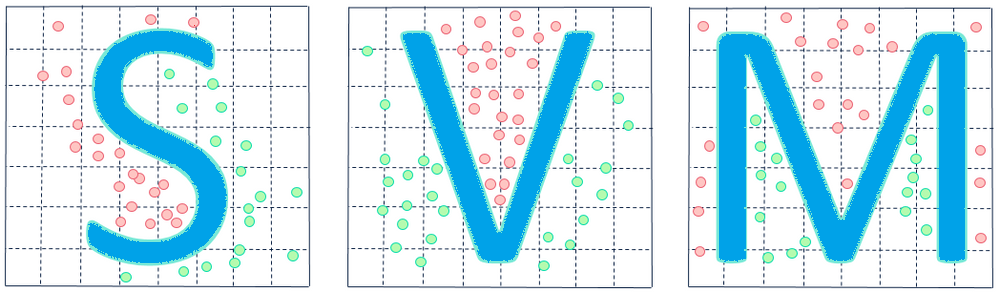
ماشینهای حامل پشتیبان (SVM): این سیستم یک ابزار پیشبینی است که میتواند طیف گستردهای از مشکلات یادگیری مانند تشخیص رقم دستنویس، طبقهبندی صفحات وب و تشخیص چهره را حل کند. این روش قادر به شناسایی فعالیتهای متقلبانه در زمان معامله است.
K- نزدیکترین همسایگان (KNN): به دلیل سادگی، به الگوریتم «یادگیری تنبل» نیز معروف است. این سیستم به جای انجام محاسبات پس از معرفی دادهها، فقط آنها را برای طبقه بندی بیشتر ذخیره میکند. الگوریتم KNN بر شباهت ویژگی و نزدیکی دادهها استوار است. هنگامی که نزدیکترین همسایه دادهای مشکوک باشد، معامله به عنوان متقلبانه و زمانی که نزدیکترین دادهی همسایه قانونی باشد، معامله در دسته قانونی قرار میگیرد.
برگشت منطقی: یک الگوریتم پیش بینی است که توسط یادگیری ماشینی از دانش آمار وام گرفته شده است. این الگوریتم به طور گستردهای برای تشخیص تقلب کارت اعتباری و امتیازدهی اعتبار استفاده میشود.

در نهایت، هدف هوش مصنوعی در زمینه کشف تقلب و جلوگیری از کلاهبرداری این است که به جای غربال کردن هزاران داده به روشی طاقت فرسا و وقت گیر ، کار عوامل انسانی را در یافتن و بررسی ادعاها و معاملات متقلبانه آسانتر کند.
بسیاری از ارائه دهندگان خدمات مالی و سازمانهای بیمه به دلیل درگیری با مسئله تقلب و هزینههای عوامل انسانی مبارزه با آن دچار محدودیت میشوند. سود پیشبینیشده از پیادهسازی فناوریهای یادگیری ماشینی در راستای کشف ناهنجاری و تقلب، بدون شک به هر سازمانی امکان رشد و توسعه میدهد.
بسیاری از شرکتهای تجاری در حال حاضر از راهحلهای خودکار شناسایی تقلب در سیستمهای خود برای جلوگیری از رفتارهای مشکوک مانند دادههای نادرست، تصاحب حساب، کلاهبرداری در پرداخت و فیشینگ استفاده میکنند.
استفاده از فناوری پیشرفته باعث افزایش اعتبار سازمانهای مالی و بیمهگر میشود و در نتیجه این سازمانها میتوانند روابط بهتری بر پایه اعتماد و وفاداری با مشتریان خود برقرار کنند.
ترجمه و تلخیص: ارژنگ طالبینژاد